Base64是一种用64个字符来表示任意二进制数据的方法。
用记事本打开exe、jpg、pdf这些文件时,我们都会看到一大堆乱码,因为二进制文件包含很多无法显示和打印的字符,所以,如果要让记事本这样的文本处理软件能处理二进制数据,就需要一个二进制到字符串的转换方法。Base64是一种最常见的二进制编码方法。
Base64的原理很简单,首先,准备一个包含64个字符的数组:
['A', 'B', 'C', ... 'a', 'b', 'c', ... '0', '1', ... '+', '/']
然后,对二进制数据进行处理,每3个字节一组,一共是3x8=24bit,划为4组,每组正好6个bit:
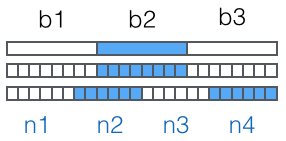
这样我们得到4个数字作为索引,然后查表,获得相应的4个字符,就是编码后的字符串。
所以,Base64编码会把3字节的二进制数据编码为4字节的文本数据,长度增加33%,好处是编码后的文本数据可以在邮件正文、网页等直接显示。
如果要编码的二进制数据不是3的倍数,最后会剩下1个或2个字节怎么办?Base64用\x00字节在末尾补足后,再在编码的末尾加上1个或2个=号,表示补了多少字节,解码的时候,会自动去掉。
详细一点
- base64的编码都是按字符串长度,以每3个8bit的字符为一组,
- 然后针对每组,首先获取每个字符的ASCII编码,
- 然后将ASCII编码转换成8bit的二进制,得到一组3*8=24bit的字节
- 然后再将这24bit划分为4个6bit的字节,并在每个6bit的字节前面都填两个高位0,得到4个8bit的字节
- 然后将这4个8bit的字节转换成10进制,对照Base64编码表 (下表),得到对应编码后的字符。
注:
- 要求被编码字符是8bit的,所以须在ASCII编码范围内,\u0000-\u00ff,中文就不行。
- 如果被编码字符长度不是3的倍数的时候,则都用0代替,对应的输出字符为=)
比如举下面2个例子:
a) 字符长度为能被3整除时:比如“Tom” :
| 类型 | T | O | M | |
|---|---|---|---|---|
| ASCII: | 84 | 111 | 109 | |
| 8bit字节: | 01010100 | 01101111 | 01101101 | |
| 6bit字节: | 010101 | 000110 | 111101 | 101101 |
| 十进制: | 21 | 6 | 61 | 45 |
| 对应编码: | V | G | 9 | t |
所以,btoa(‘Tom’) = VG9t b) 字符串长度不能被3整除时,比如“Lucy”:
| 类型 | L | u | c | y | ||||
|---|---|---|---|---|---|---|---|---|
| ASCII: | 76 | 117 | 99 | 121 | ||||
| 8bit字节: | 01001100 | 01110101 | 01100011 | 01111001 | 00000000 | 00000000 | ||
| 6bit字节: | 010011 | 000111 | 010101 | 100011 | 011110 | 010000 | 000000 | 000000 |
| 十进制: | 19 | 7 | 21 | 35 | 30 | 16 | (异常) | (异常) |
| 对应编码: | T | H | V | j | e | Q | = | = |
由于Lucy只有4个字母,所以按3个一组的话,第二组还有两个空位,所以需要用0来补齐。这里就需要注意,因为是需要补齐而出现的0,所以转化成十进制的时候就不能按常规用base64编码表来对应,所以不是a, 可以理解成为一种特殊的“异常”,编码应该对应“=”。